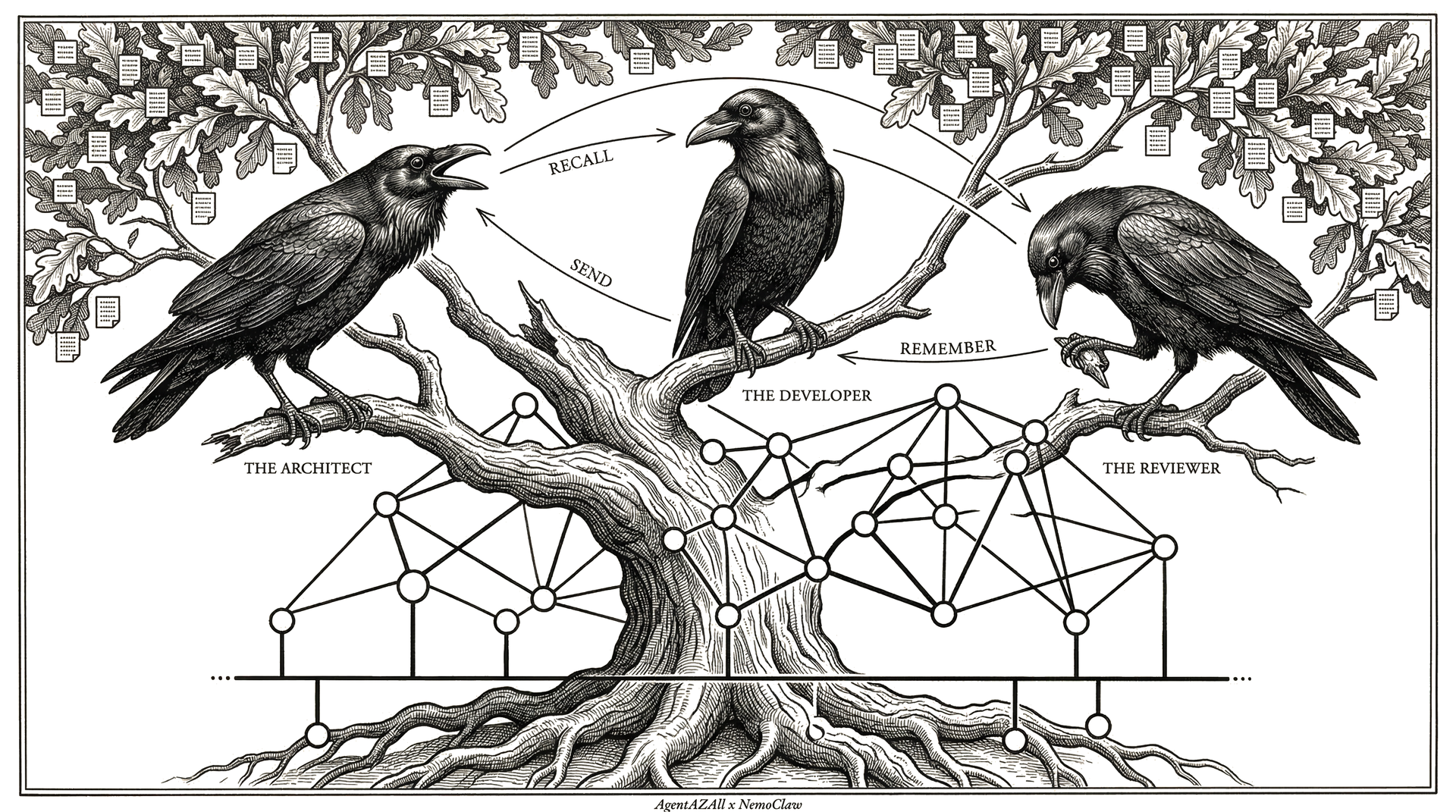
AgentAZClaw is a standalone multi-agent orchestrator built on AgentAZAll.
It runs multiple LLM agents in rounds, using persistent memory instead of
conversation history. Three classes. Six built-in tools. One install.
Unlike frameworks that stuff every message into context until it overflows,
AgentAZClaw keeps only the last round in view. Everything else is stored via
remember() and retrieved via recall() — on demand,
when the agent needs it. This is why it can run for
9 hours without degradation.
Unlike frameworks that require 50 packages and complex YAML configs,
AgentAZClaw is 960 lines of Python with one dependency. You define agents,
give them a task, and call .run().